Observer
The Datalayer Observer Helm Chart installs the needed Observability tooling for the Datalayer Platform to be operated in production.
Tooling
OpenTelemetry Collector
The OpenTelemetry Collector is used:
- As Kubernetes Deployment to proxy metrics and traces from Datalayer services to Prometheus and Tempo.
- As Kubernetes Daemonset to parse pod log files and send them to Loki.
Prometheus
Prometheus is used to gather metrics.
Tempo
Tempo is used to gather traces.
Loki
Loki is used to gather logs of all the services in a central place.
Alert Manager
Prometheus Alert Manager is used to create and manage the alerts.
Grafana
Grafana is used to visualize and analyze the gathered information.
How to Install?
plane up datalayer-observer
The first time, you will likely get an error preventing the Opentelemetry collectors to
be created. Executing the up command a second time should pass.
If you face some issues due to the OpenTelemetry operator, it is likely
related to the CRDs being undefined in the cluster. You can install them
manually from plane/etc/helm/charts/datalayer-observer/charts/crds/crds.
Helm should install them the first time. But this is a complex thing to handle; see https://helm.sh/docs/chart_best_practices/custom_resource_definitions/#install-a-crd-declaration-before-using-the-resource
What is Deployed?
This chart is built on top of multiple subcharts:
kube-prometheus-stack- Full Prometheus stack activating:- AlertManager
- Grafana
- Prometheus Operator
- Prometheus
- Prometheus Node Exporter
loki- Loki as single binary
tempo- Tempo as single binary
opentelemetry-operator- using collector-contrib image
In addition to the subcharts elements, it creates:
- An OpenTelemetry collector as singleton instance to proxy traces and metrics from services to Prometheus and Tempo
- An OpenTelemetry collector as daemonset to parse the container log files and proxy them to loki
- A custom ingress for grafana to use similar config as for Datalayer services
- A service monitor to tell prometheus to fetch the metrics:
- from the OpenTelemetry collector singleton
- from the Remote Kernels (currently we use the Jupyter Server prometheus endpoint)
- Cluster roles for the OpenTelemetry collectors in order to use the Kubernetes API to fetch pod/node metadata to enrich the telemetry metadata.
Currently no traces are observed for the Remote Kernels.
Telemetry Metadata
Opentelemetry requires the services to be distinguished using a triplet (service.name, service.namespace, service.instance.id) - only the first one is mandatory. But Prometheus requires services to be distinguished using a doublet (job or pod, instance).
Terefore as recommended in Opentelemetry documentation, the following mapping is applied: job == service.namespace; instance == service.instance.id.
Those metadata are set from:
service.name:- Enforce on telemetry send by datalayer services
- Extracted from container name for logs
service.namespace: Kubernetes namespaceservice.instance.id: Kubernetes pod id
The other metadata normalized (in Loki, Tempo and Prometheus) are:
app: Kubernetes pod labeldatalayer.io/appnamespace: Kubernetes namespacepod: Kubernetes pod namecluster: Value from$DATALAYER_RUN_HOSTinstance: Kubernetes instance
For Remote Kernels, the following metadata are also added:
datalayer.pool.name: Kubernetes labeljupyterpool.datalayer.io/namedatalayer.pool.status: Kubernetes labeljupyterpool.datalayer.io/pod-statusdatalayer.pool.user: Kubernetes labeljupyterpool.datalayer.io/user-uiddatalayer.pool.type: Kubernetes labeljupyterpool.datalayer.io/kernel-typedatalayer.pool.reservation: Kubernetes labeljupyterpool.datalayer.io/reservation-id
How to Uninstall?
plane down datalayer-observer
The Opentelemetry collectors will unfortunately not be removed - the associated CRs are failing to be deleted.
You will need to edit them manually to remove the finalizer (as the OpenTelemetry operator is down).
Then normally all associated Pods should be removed.
Tips and Tricks
Grafana
Grafana will be available on this URL.
open ${DATALAYER_RUN_URL}/grafana
If you did not set an admin password, it was set using a random string in Kubernetes secret. You can print it by executing the following command.
kubectl get secret --namespace datalayer-observer \
-l app.kubernetes.io/name=grafana \
-o=jsonpath="{.items[0].data.admin-password}" | base64 --decode
echo
Use the admin and the printed password credentials to connect via the Grafana Web page.
Telemetry Exploration
Grafana is the de-facto tool for exploring all telemetry (logs, traces and metrics); in particular the Explore panel.
For Tempo, you can query the data using the Search method and setting a Service name. Traces are usually not the best places to start - better use logs that will link the associated trace.
For Loki, you can query using a label filter on service_name (e.g. iam). When clicking on a log entry, you will access its metadata and a link to the associated trace (if available).
For Prometheus, you can query using a label filter on service_name (e.g. iam). It is usually easier than starting with a metric names as those are not standardize across services (neither in name nor in unit - that appears in the name).
Prometheus
Prometheus gets its data source definition from CRs PodMonitor and ServiceMonitor (recommended). Third-parties that don't support OpenTelemetry metrics use such monitors and therefore are not proxied by the OpenTelemetry collector.
Firstly:
ServiceMonitor- Used by Grafana, AlertManager, Loki, Tempo, Prometheus, PrometheusOperator, Prometheus Node Exporter and OpenTelemetry Collector singleton.
- To be detected by Prometheus the ServiceMonitor must have the two labels:
monitoring.datalayer.io/instance: "observer"
monitoring.datalayer.io/enabled: "true"
- Kubernetes metrics are also gathered through service monitors defined in the kube-prometheus-stack.
Secondly:
PodMonitor: used by Pulsar stack (default in the Helm Chart).- PodMonitor can be defined in any namespace
- To be detected by Prometheus the PodMonitor must have a label
app=pulsar. Other app name could be defined in thekube-prometheus-stack.prometheus.prometheusSpec.podMonitorSelector.
Instrumentation
Datalayer Services
The services based on connexion are instrumented explicitly using the code
defined in datalayer_common.instrumentation as a custom version of the
Python instrumentation ASGI was needed in particular to push the http route
metadata.
The logging instrumentor is used as by default it calls basicConfig. The service must not call it.
Configuring the metrics and traces targets is done through environment variables:
export OTEL_EXPORTER_OTLP_METRICS_ENDPOINT=http://datalayer-collector-collector.datalayer-observer.svc.cluster.local:4317
export OTEL_EXPORTER_OTLP_TRACES_ENDPOINT=http://datalayer-collector-collector.datalayer-observer.svc.cluster.local:4317
Currently the data is sent using gRPC.
HTTP is also available but would require to change the instrumentation code as the library to use is different.
Jupyter Remote Kernels
There is for now no custom instrumentation, nor custom log format. Only metrics from the standard Jupyter Server prometheus endpoint are gathered.
Non-working instrumentation
Auto-instrumentation by the OpenTelemetry operator
via a CR Instrumentation was tried but it did not work.
That CR must be defined in the namespace the pod are gonna be created and the instrumentation will occur only at the pod creation.
A pod is selected for instrumentation if it gets some annotations. In this specific case, to instrument Python on a multi-container pod:
instrumentation.OpenTelemetry.io/inject-python: "true"
instrumentation.OpenTelemetry.io/container-names: "{KERNEL_CONTAINER_NAME}"
See this README for more information and available options (to be set through environment variables).
The Python auto-instrumentation is using http to send data to the OpenTelemetry Collector.
Grafana Dashboards
On top of the standard technical stack (Pulsar, Ceph...) dashboards, we have prepared custom dashboards to help with the observation.
The dashboards definitions are available in this public GitHub repository.
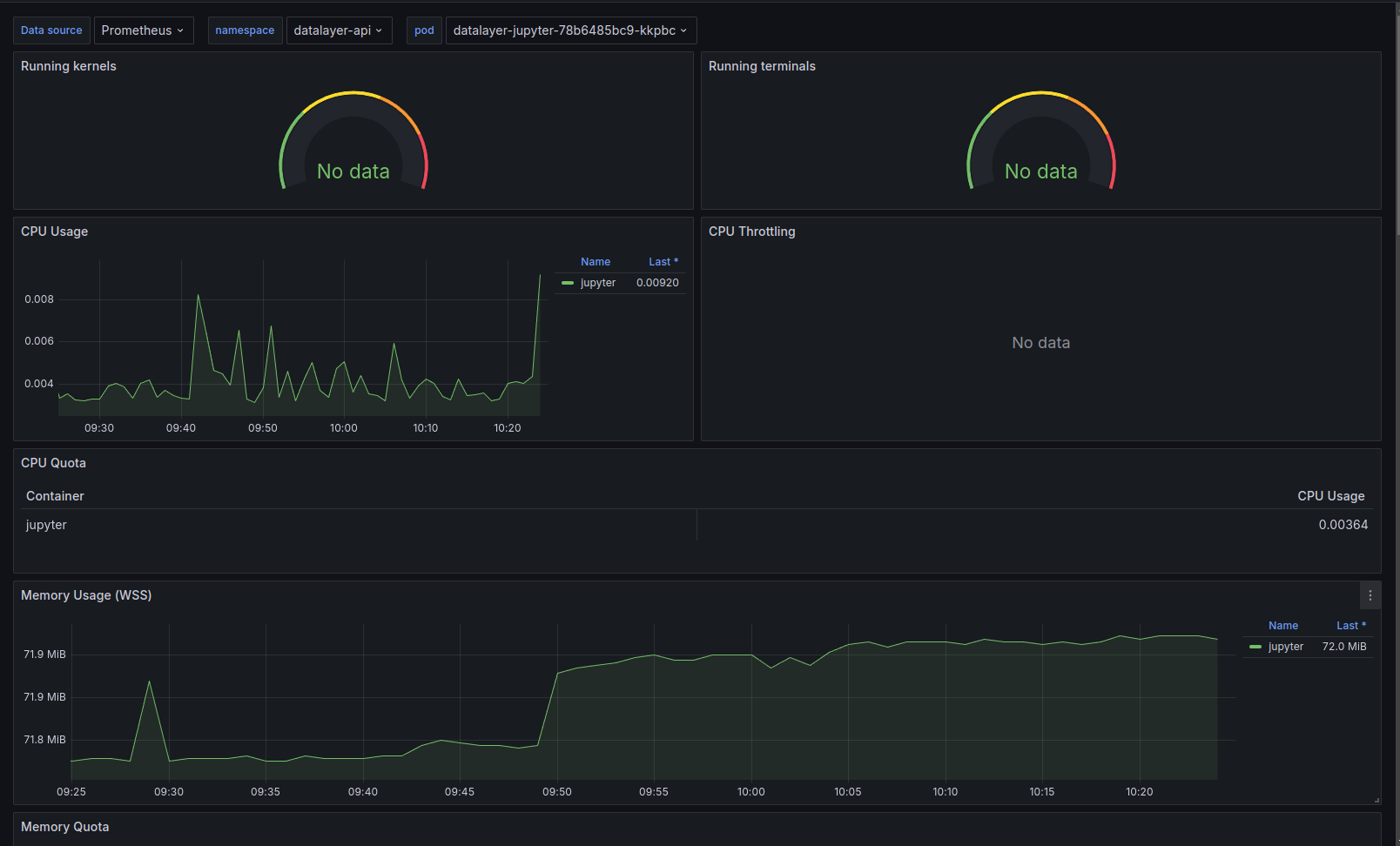
Services
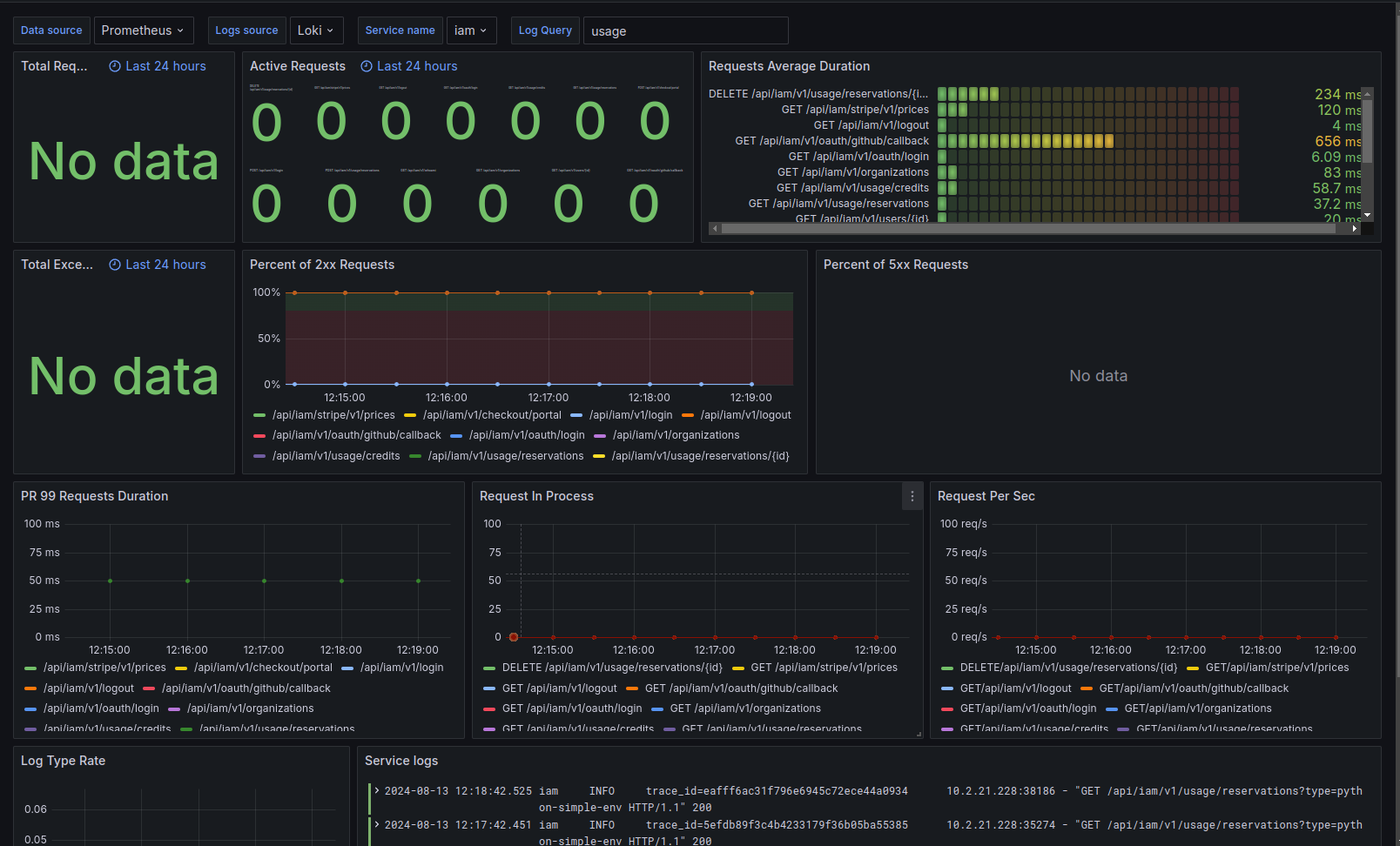
Overall View
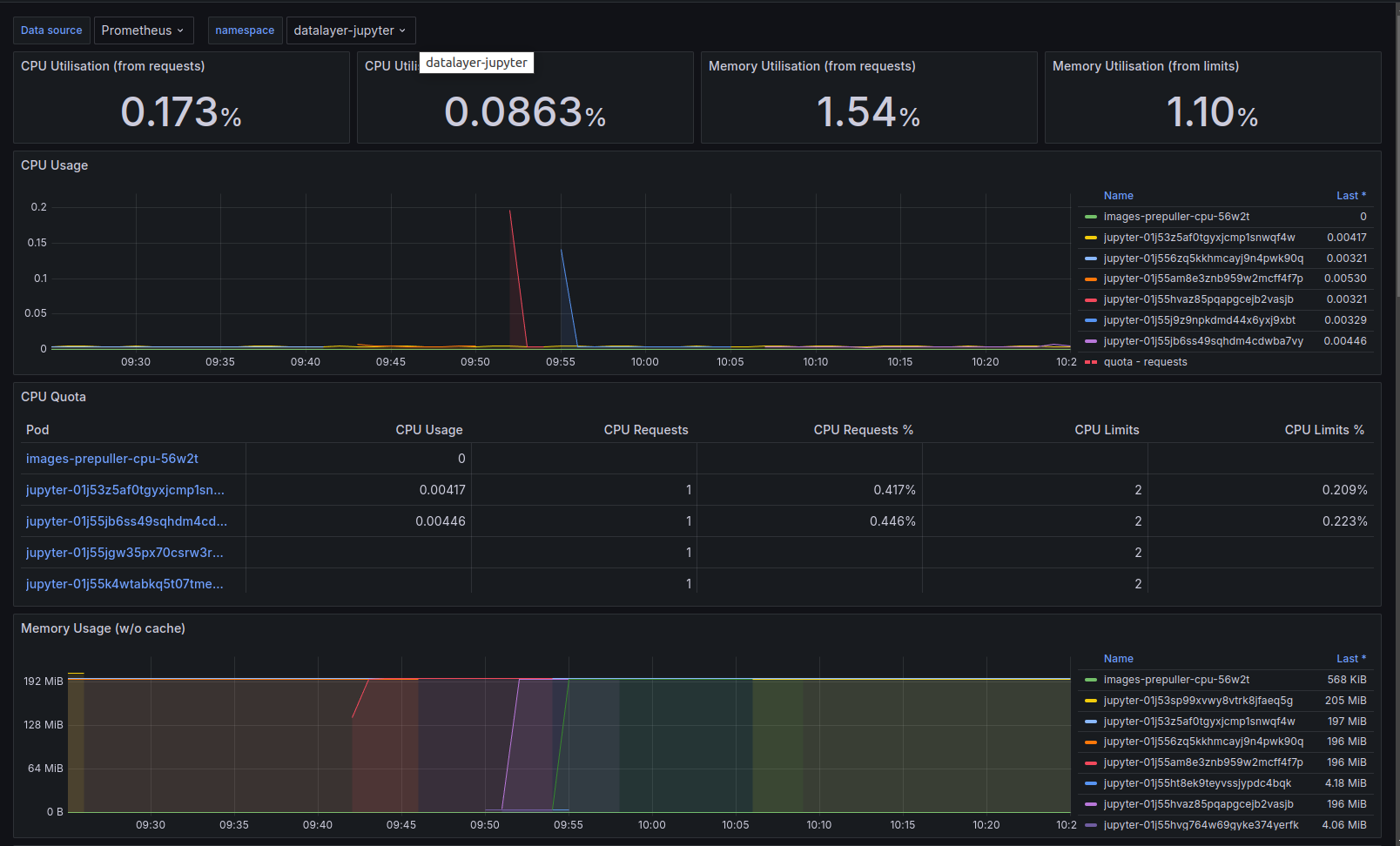
Detailed View